Group in Charge: PI Aurélie CLODIC group (FR), Co-PI Michael BEETZ group (GER)
WP4 is dedicated to Joint Action Planning and Execution. We have always considered three main challenges for this workpackage. The first one is to consider not a one to one but a one to many interaction. The second one is to consider both long term and short term interaction. The third one is to consider the social context. While the development of the project (final) supervision and planning system is still in progress, we will show here the development of the needed building blocks that has realized so far.
Supervision System Requirements
From our previous works, we defined a set of requirements for supervision system in a human-robot interaction setting that we used as guidelines along the project:
- 1) Be generic. The objectives developed in the rest of this list are valid for most collaborative tasks. Thus, it is essential to develop a software not dedicated to a particular task but able to handle plans for various tasks.
- 2) Take explicitly into account the human partner. In HRI, the human and the robot are partners. Partners perform better when taking each other into account. Thus, by considering human abilities, perspective and mental states to make decisions, a supervisor makes the robot a better partner for the human.
- 3) Leave decisions to the human. In some cases, it is not useful, even counterproductive that the robot plans everything beforehand. Indeed, such elements such as the human action parameters, or who should execute a given action when it does not matter, or the execution order of some actions, can be decided at execution time.
- 4) Recognize human actions. To monitor the plan progress, the robot should be able to monitor the human by recognizing their actions.
- 5) Handle contingencies. The robot has a shared plan, that is one thing, but executing it and achieving the goal is another. Indeed, it is not sure that the human has exactly the same, and errors or failures can happen. Thus, it should be able to handle a number of contingencies.
- 6) Manage relevant communications. Communication is one of the keys of collaboration. Therefore, it is important to endow the robot with the ability to manage relevant communication actions, verbal and non-verbal.
- 7) Consider the interaction outside collaborative tasks. A robot dedicated to collaborative tasks, in a real-life context, will interact with humans outside or between these tasks. We propose to consider this fact by defining what we called interaction sessions, allowing to take into account facts from one task/session to another.
- 8) Ensure adaptation. Ensure adaptation to the human experience, abilities or preferences.
- 9) Reproducibility. Code availability of the software
Achievement and Related publication:
Amandine Mayima, Aurélie Clodic, Rachid Alami. JAHRVIS, a Supervision System for Human-Robot Collaboration. 31st IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2022), Aug 2022, Napoli, Italy. ⟨10.1109/RO-MAN53752.2022.9900665⟩. ⟨hal-03702389⟩
https://laas.hal.science/hal-03702389
The supervision component is the binder of a robotic architecture. Without it, there is no task, no interaction happening, it conducts the other components of the architecture towards the achievement of a goal, which means, in the context of a collaboration with a human, to bring changes in the physical environment and to update the human partner mental state. However, not so much work focus on this component in charge of the robot decision-making and control, whereas this is the robot puppeteer. Most often, either tasks are simply scripted, or the supervisor is built for a specific task. Thus, we propose JAHRVIS, a Joint Action-based Human-aware supeRVISor. It aims at being task-independent while implementing a set of key joint action and collaboration mechanisms. With this contribution, we intend to move the deployment of autonomous collaborative robots forward, accompanying this paper with our open-source code.
Mutual expectations management to facilitate coordination in joint action
An important number of social interactions and encounters that we face in everyday life are encompassed by the notion of joint action. Broadly considered, a joint action is any form of social interaction where two or more participants coordinate their actions in space and time to bring about a change in the environment [Sebanz2006, p70]. Given the importance of joint action for human sociality, designing social robots able to interact with humans to perform joint actions is a fundamental challenge in human-robot interaction studies and social robotics. But what strategy one may design to advance to this challenge?
We propose that the notion of commitment plays a fundamental role in how humans respond and coordinate in joint actions. We aim at showing that social robotics may benefit from developing and designing commitment-based approaches to human-robot interaction. In particular, by modelling and taking advantage of situated expectations. Elaborating upon philosophical literature on commitments, we argue that commitments facilitate (1) the recognition of expectations among partners; and (2) the establishment of regulative strategies when an expectation is frustrated, which facilitates reciprocation and repair during joint action.
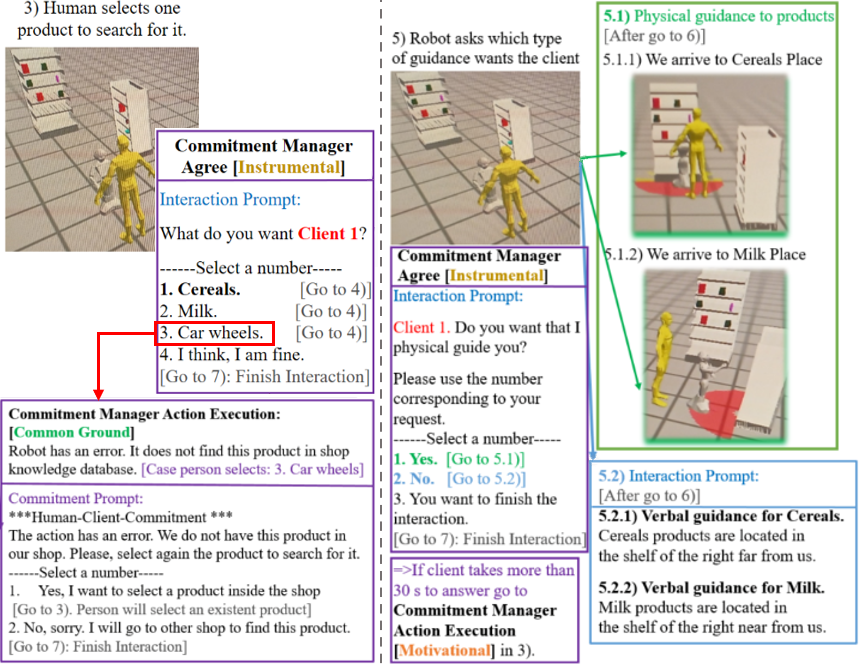
Achievements and Related publications:
We have a first contribution where we explore theoretically how commitments may be a fundamental element in human-robot joint actions. Then, we implemented a proof of concept based on a simulated retail store scenario. We are now in the process to push these ideas at a more general level to be used on our retail store use-case.
Victor Fernández Castro, Amandine Mayima, Kathleen Belhassein, and Aurélie Clodic (in press) “The Role of Commitments in Socially Appropriate Robotics” In Gransche, M. Nerurkar, J. Bellon, S. Nähr-Wagener (eds) Technology Socialization? Social appropriateness for computer-based systems. Springer.
In this chapter, we explore theoretically how commitments may be a fundamental element in human-robot joint actions and in the design of socially appropriate robots. We sketch a particular framework of how a robotic architecture for commitment may capture the two aspects and how they can be modelled. We conclude with some remarks regarding the long-range consequences and considerations of introducing the notion of commitment in the research on social robotics and its role concerning sociality and social appropriateness.
Ely Repiso, Guillaume Sarthou, Aurélie Clodic. Towards a system that allows robots to use commitments in joint action with humans. IEEE RO-MAN 2023, Aug 2023, Busan (Corée), South Korea. ⟨hal-04206081⟩ \url{https://laas.hal.science/hal-04206081}
In this paper, we present an implemented proof of concept system using commitments in human-robot interaction management. It focuses on reducing normative expectations that can be of three types: motivational, instrumental and common ground. We have applied these theories in a simulated Human-robot interaction, see Figure wp4.1. Where the robot has two possible plans, greetings and helping the human to search for a product in the shop. In this interaction, there are several examples of our commitment types to be handled, like knowing if the person is motivated to start, continue the interaction or finish it; solving uncertainties about how to execute an action like verbal or physical guidance; and solving uncertainties about common knowledge of the product availability in the shop. Finally, this work can be improved in the future.
What is behind social context?
The notion of social context could be defined as the set of elements impacting the way the robot should interpret and behave in a given situation. Let’s take an example. In our retail store, some locations are linked to some actions that can hold only in that particular location (and not somewhere else), that could be linked to different roles that could be taken by the agent (but not necessarily). For example, only near the cash register, an employee could become a cashier and be able to handle the payment of a customer. A location can take a particular meaning given the context evolution. For example, the customer enters by the retail store entrance but exits through the retail store exit, which refers in fact to the same place. Object characteristics can change along the context evolution. For example, in our retail store example, the customer becomes the owner of a product, only when he has paid it. Before, the product is owned by the retail store (and if the customer escaped with it, it is a theft).
To be able to take into account the notion of context, we implemented the notion of context representation in our ontology-based system Ontologenius. It has been complement by a context reasoner that is able to determine the active context of an agent using the perceived activity, location, and role of the agent. Figure wp4.2 shows an example for a context of a theater classroom.

Achievements and Related publication:
Adrien Vigné, Guillaume Sarthou, Ely Repiso, Aurélie Clodic. In which context are we interacting? A Context Reasoner for interactive and social robots. Artificial Intelligence for Social Robots Interacting with Humans in the Real World [intellect4hri workshop@IROS], Oct 2022, Kyoto, Japan. ⟨hal-04183981⟩ http://hal.science/hal-04183981
To effectively interact with others, one has to understand the context in which the interaction takes place. This understanding allows us to know how to act, how to interpret others' actions, and thus how to react. In this paper, we first present a basic formalism of the notion of context through the use of an ontology in order to integrate the new piece of information into a robot knowledge base in a coherent way. From there, we present a Context Reasoner integrated into the robot's knowledge base system allowing it to identify the context in which it is interacting but also to identify the current context of the surrounding humans. The effectiveness of this Context Reasoner and its underlying representation of the context is demonstrated in a simulated but dynamic situation where a robot observes an interaction between two humans. This work is an initial step to endow robots with the ability to understand the nature of interactions. We think that this basis will help to develop higher decisional processes able to adapt the robot's behaviors depending on the nature of the interaction.
From situation assessment to action and task recognition using perspective taking
Where robots have been restricted for a while at performing complex tasks on their own in an autonomous way, or in coordination with other robotic agents, the field of Human-Robot Interaction brings the new challenge of robots performing shared tasks with humans. In light of the definition of joint action, this means that robots should be able to interact with humans and coordinate their actions in space and time to bring about a change in the environment [Sebanz2006]. Cooperation and collaboration tend to be key features to make robots more adaptative and thus flexible with respect to humans’ actions.
As a prerequisite to joint action, Tomasello in [Tomasello2005] emphasized intentional action understanding, meaning that an agent should be able to read its partner’s intentions. In this way, when observing a partner’s action or course of actions, the agent should be able to infer its partner’s intention in terms of goal and plan to achieve the goal. Where in a shared task one can assume a shared goal to exist, a shared plan can only be estimated by both partners. As a consequence, during the entire realization of a shared task, agents should continue to monitor others’ actions to be able to adapt and coordinate their own actions. That’s why we developed an Action Recognition System. This system is based on semantic abstraction of changes in the environment.
In order to be fed with meaningful semantic facts representing the changes in the environment, our Action Recognition System has been integrated into the DACOBOT [Sarthou2021] robotic architecture and follows the knowledge flow illustrated in Figure wp4.3.
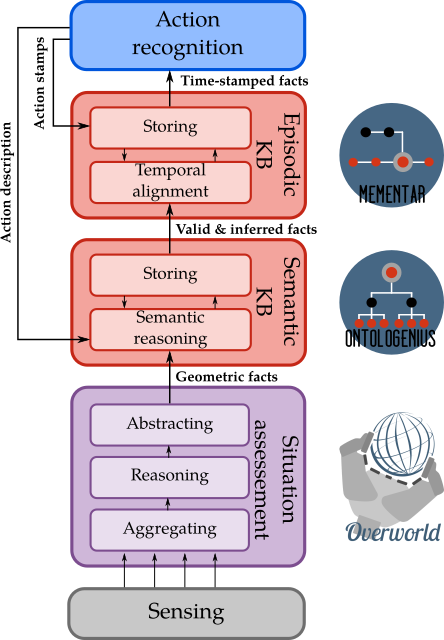
In this architecture, the geometrical Situation Assessment is handled by the software Overworld [Sarthou2023]. This software can be connected to any perception system to perceive objects, humans, or areas. As the same entity can be perceived through several systems, Overworld is first able to aggregate the data from all the used perception systems to create a unified 3D representation of the robot’s environment. Thanks to geometrical reasoning based on the sensors’ field of view, the entities’ visual occlusions, and physics simulation, Overworld provides a coherent representation of the entire environment. On the basis of the 3D representation, Overworld can then compute semantic facts. These facts can link objects together like with isOnTopOf or isInContainer. They can link objects or agents to areas with isInArea. They can also link agents to objects with facts such as hasInHand, isLookingAt, or hasHandMovingToward. These facts are computed at every update of the system and are output on a ROS topic. A fact is generated when it starts to be perceived (ADD) and when it stops (DEL). An important feature of Overworld, essential for HRI, is its ability to estimate the perspective of other agents and their representation of the world. From there, in the same way it is done from the robot’s perspective, Overworld computes and generates semantic facts from the others’ perspective allowing the use of the theory of mind.
The architecture used considers as a central component a semantic knowledge base. This latter contains both common sense knowledge (general concepts like object types, colors, …) and anchored knowledge related to the current situation. This knowledge can be accessed by every component of the architecture allowing a unified and coherent representation among the entire architecture.
This semantic knowledge base is managed by Ontologenius [Sarthou2019]. This software has been specially developed for robotic applications with good performances both on queries and dynamic updates. It is thus adapted to maintain the current state of the situation at a semantic level with online inferences resolutions. Regarding the knowledge stream, Ontologenius is directly connected to the output of Overworld. When new facts arrive in it, they are first analysed to verify their consistency regarding common sense knowledge, then once added to the knowledge, Ontologenius will reason on this knowledge in order to extract new facts. For example, from the fact ADD~(cup_1~isInTopOf~table_3), we can infer thanks to inverse ADD~(table_3~isUnder~cup_1). As an output, Ontologenius sends on a ROS topic the validated facts as well as the inferred ones. However, as it does not deal with temporal aspects, the inferred facts cannot be stamped on the base of the used facts for the inference nor at the time of the inference. They are rather sent with an explanation about the facts involved in their inference. Like Overworld, Ontologenius can maintain several knowledge bases in parallel, allowing theory of mind. Each output of Overworld (one per human agent in addition to the robot) is thus connected to a specific knowledge base.
As explained by Riboni et al. in [Riboni2011], ontology-based action recognition is possible when linked to time representation. Regarding this temporal representation, the DACOBOT architecture proposes the software Mementar (https://github.com/sarthou/mementar) as an episodic knowledge base. It is responsible for the organization of the semantic facts, provided by the ontology, on a temporal axis. While only the validated facts are already stamped, the inferred ones have to be aligned. To this end, Mementar finds the more recent fact among the ones used in the inference and aligns the inferred fact on this later. All the facts once correctly stamped are then republished on a ROS topic for the components (as the action recognition) needing continuous monitoring. On the basis of this timeline, Mementar proposes a set of queries to retrieve past facts based on their timestamp, their order, or their semantics thanks to a link with the semantic knowledge base. In addition, Mementar allows to represent actions/tasks in the timeline with a start stamp and an end stamp. These actions can also be queried to retrieve the facts appearing during an action, the actions holding during an action, their stamps, or their type. Finally, in the same way it has been done for the two previously presented components, Mementar can manage a timeline per agent allowing to manage theory of mind at a temporal level.
Our Action Recognition system is connected to the output of Mementar where no distinction is made between the inferred facts and the others. As illustrated in Figure wp4.3, as an output, the action recognition sends the description of the recognised actions to the semantic knowledge base and temporally marks them in the episodic knowledge base.
Achievement and Related publications:
We implemented a primitive action recognition system and a task recognition system. We proposed also a way to represent affordances in ontology-based system.
Adrien Vigné, Guillaume Sarthou, Aurélie Clodic, Primitive Action Recognition based on Semantic Facts, 15th International Conference on Social Robotics, ICSR 2023.
To interact with humans, a robot has to know actions done by each agent presents in the environment, robotic or not. Robots are not omniscient and can't perceive every actions made but, as humans do, we can equip the robot with the ability to infer what happens from the perceived effects of these actions on the environment.
In this paper, we present a lightweight and open-source framework to recognise primitive actions and their parameters. Based on a semantic abstraction of changes in the environment, it allows to recognise unperceived actions. In addition, thanks to its integration into a cognitive robotic architecture implementing perspective-taking and theory of mind, the presented framework is able to estimate the actions recognised by the agent interacting with the robot. These recognition processes are refined on the fly based on the current observations. Tests on real robots demonstrate the framework's usability in interactive contexts.
Adrien Vigné, Guillaume Sarthou, Aurélie Clodic, Semantic shared-Task recognition for Human-Robot Interaction, ROMAN2024.
When collaborating with humans during a shared task, a robot must be able to estimate the shared goal and monitor the tasks completed by its partners to adapt its behavior. Our contribution is a lightweight, hierarchical task recognition system that enables the robot to estimate shared goals and monitor human tasks. This recognition system is integrated into a robotic architecture to take advantage of the semantic knowledge flow available and builds upon our previous work on action recognition. We demonstrate the mechanisms of our recognition system and how we improved it to handle missing information using a kitchen scenario. This also enables us to showcase its usability from the perspective of other agents, using Theory of Mind.
Bastien Bastien Dussard, Aurélie Clodic, Guillaume Sarthou, Agent-Exploitation Affordances: From Basic to Complex Representation Patterns, ICSR2024.
In robotics, the capability of an artificial agent to represent the range of its action possibilities, i.e. affordances, is crucial to understand how it can act on its environment. While functional affordances, which refer to the use of tools and objects, have been broadly studied in knowledge representation, the implications of a social context and the presence of other agents have remained unexplored in this field. Consequently, in the field of social robotics, a multi-agent context enables the agents to engage in new actions that are potentially complementary to their individual capabilities, leading to the perspective of agentexploitation. This work focuses on the concept of cooperative affordance within the realm of social affordances. Cooperative affordances refer to situations where agents interact with each other to extend their action possibilities range. From this definition, this paper proposes a tractable ontological representation of this concept with the aim of making it usable by an artificial agent. Expanding on those elementary patterns, we illustrate the effectiveness of these representations by combining them to depict a diverse range of scenarios.
Navigation seen as a joint action
Considering that we want the robot to navigate in the retail store and be able to guide customers, we have done some work related to robot navigation and guidance. For the robot navigation, we have studied how to navigate in the presence of humans in a social adequate manner. For example, crossing situations may be considered carefully and the interaction may benefit from the use of cues such as robot’s « head » move or trajectory adaptation (See Figure wp4.4). Regarding robot guidance, we have modified an existing human-robot collaborative planner to accompany people [Repiso2022] to be able to guide people to some locations. This new implementation also considers when people stop to go back, to make it easy for people to follow the robot (See Figure wp4.5). In the future, it can also include other behaviors to facilitate the guidance. Additionally, we developed metrics to evaluate the robot behavior quantitatively and qualitatively during navigation. Furthermore, for better human-robot interactions, it is also good that the robot will detect the familiarity between humans when walking to be able to modify its behavior in consequence. Due to that, we have studied and classified the different types of human-human relations while walking: couple, family, friends, and colleagues.

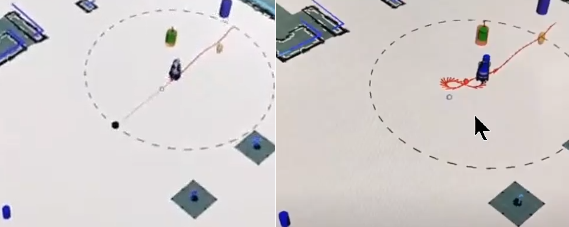
Achievements and Related publications:
Guilhem Buisan, Nathan Compan, Loïc Caroux, Aurélie Clodic, Ophélie Carreras, et al.. Evaluating the Impact of Time-to-Collision Constraint and Head Gaze on Usability for Robot Navigation in a Corridor. IEEE Transactions on Human-Machine Systems, Oct 2023, pp.1-10. ⟨10.1109/THMS.2023.3314894⟩. ⟨hal-04240696⟩ https://hal.science/hal-04240696
To effectively interact with others, one has to understand the context in which the interaction takes place. This understanding allows us to know how to act, how to interpret others' actions, and thus how to react. In this paper, we first present a basic formalism of the notion of context through the use of an ontology in order to integrate the new piece of information into a robot knowledge base in a coherent way. From there, we present a Context Reasoner integrated into the robot's knowledge base system allowing it to identify the context in which it is interacting but also to identify the current context of the surrounding humans. The effectiveness of this Context Reasoner and its underlying representation of the context is demonstrated in a simulated but dynamic situation where a robot observes an interaction between two humans. This work is an initial step to endow robots with the ability to understand the nature of interactions. We think that this basis will help to develop higher decisional processes able to adapt the robot's behaviors depending on the nature of the interaction.
Ely Repiso, Anaís Garrell, Alberto Sanfeliu. Real-Life Experiment Metrics for Evaluating Human-Robot Collaborative Navigation Tasks. IEEE RO-MAN 2023, Aug 2023, Busan (Corée), South Korea. ⟨hal-04206085⟩ https://laas.hal.science/hal-04206085v1
As robots move from laboratories and industries to the real world, they must develop new abilities to collaborate with humans in various aspects, including human-robot collaborative navigation (HRCN) tasks. Then, it is required to develop general methodologies to evaluate these robots' behaviors. These methodologies should incorporate objective and subjective measurements. Objective measurements for evaluating a robot's behavior while navigating with others can be accomplished using social distances in conjunction with task characteristics, people-robot relationships, and physical space. Additionally, the objective evaluation of the task must consider human behavior, which is influenced by changes and the structure of their environment. Subjective evaluations of robot's behaviors can be conducted using surveys that address various aspects of robot usability. This includes people's perceptions of their interaction during their collaborative task with the robot, focusing on aspects such as sociability, comfort, and task-intelligence. Moreover, the communicative interaction between the agents (people and robots) involved in the collaborative task should also be evaluated. Therefore, this paper presents a comprehensive methodology for objectively and subjectively evaluating HRCN tasks.
Oscar Castro, Ely Repiso, Anaís Garrell, Alberto Sanfeliu. Classification of Humans Social Relations Within Urban Areas. Cham : Springer International Publishing, p. 27-39, 2022, 978-3-031-21065-5. ⟨hal-04205911⟩ https://laas.hal.science/hal-04205911v1
This paper presents the design of deep learning architectures which allow to classify the social relationship existing between two people who are walking in a side-by-side formation into four possible categories-colleagues, couple, family or friendship. The models are developed using Neural Networks or Recurrent Neural Networks to achieve the classification and are trained and evaluated using a database obtained from humans walking together in an urban environment. The best achieved model accomplishes a good accuracy in the classification problem and its results enhance the outcomes from a previous study. In addition, we have developed several models to classify the social interactions in two categories-"intimate" and "acquaintances", where the best model achieves a very good performance, and for a real robot this classification is enough to be able to customize its behavior to its users. Furthermore, the proposed models show their future potential to improve its efficiency and to be implemented in a real robot.
In addition to the work done in these publications, we have been able to deploy the guidance task on a PR2 robot in simulation at LAAS.
Support shopkeepers in client service
One of the challenge we want to tackle is to be able to consider one-to-many interaction. To that end, we consider the scenario where the robot has to interact, as an employee, with a customer and another employee of the retail store at the same time. While we had other model-based approaches in mind, we take the opportunity to analyse how we can take advantage of the use of Large Language Models in tackling such scenario.
By identifying what the human knows, the robot can help him by providing the necessary missing information in each circumstance. For example, in our retail store use case, the robot can proactively help employees with customer service by providing the up-to-date information about the product’s price or availability in the shop when these product characteristics change suddenly due to discounts or if other employees sell some products. Then, we have implemented a hierarchical task architecture combining different tasks, subtasks, and actions to obtain a modular system that allows to extract what is the employee’s knowledge about product characteristics and be able to help him in two situations: when he does not know the information or when his knowledge is not up-to-date respect to all products’ characteristics included in the shop database (see Figures wp4.6 and wp4.7), which must be updated with the most recent information. When the robot detects these two cases, it can advertise (using text or voice) to the human-shopkeeper about this change of the information to provide a better service to the client. Our actions are implemented using One shot learning methods that allow us to obtain our system quicker and easier.
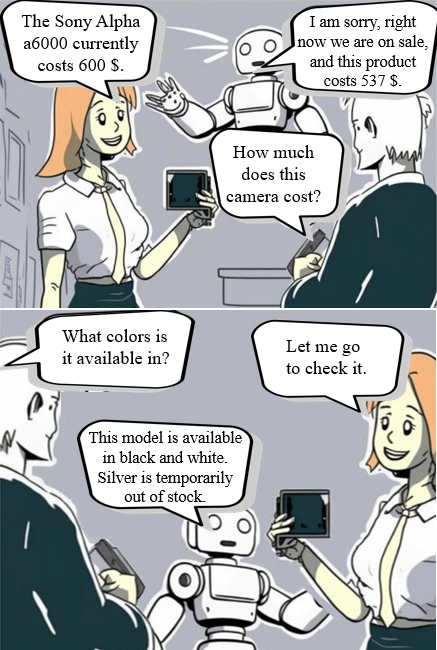

Achievements and Related publications:
We have implemented this task as a proof of concept on a Pepper robot at LAAS and tested with a previous Human-Human database of Kyoto University.
Handle short-term interactions with customers
In the same vein as the previous work, we questioned ourselves on how Large Language Models can be used to tackle human-robot interaction.
In that particular case, to deal with short-term interactions with customers, we developed a system where the robot can help when no employees are available. For this robot behavior, we consider the robot as an expert employee that has all the products’ information up-to-date by using a shop database. Additionally, it can use multimodal perception (vision and speech) as well as voice to communicate with the client. To be able to deal with uncertainties related to the product of interest, this system includes a behavior to ask for clarifications about the product by asking the person to select one of the possible product candidates included in the shop-database, as Figures wp4.6 and wp4.7 shows. This system includes actions created with Zero-Shot learning for speech and vision interactions, similar to the previous system.
Related Publication and Achievement
We have implemented this task as a proof of concept on a Pepper robot at LAAS.
References
[Repiso2022] Repiso, E., Garrell, A., and Sanfeliu, A. (2022). Adaptive social planner to accompany people in real-life dynamic environments. International Journal of Social Robotics, pages 1–33.
[Riboni2011] Riboni, D., Pareschi, L., Radaelli, L., and Bettini, C. (2011). Is ontology-based activity recognition really effective? In PERCOM workshops. IEEE.
[Sarthou2019] Sarthou, G., Clodic, A., and Alami, R. (2019). Ontologenius: A long-term semantic memory for robotic agents. In IEEE RO-MAN.
[Sarthou2021] Sarthou, G., Mayima, A., Buisan, G., Belhassein, K., and Clodic, A. (2021). The Director Task: a psychology-inspired task to assess cognitive and interactive robot architectures. In IEEE RO-MAN.
[Sarthou2023] Sarthou, G. (2023). Overworld: Assessing the geometry of the world for human-robot interaction. Robotics and Automation Letters.
[Sebanz2006] Sebanz, N., Bekkering, H., and Knoblich, G. (2006). Joint action: bodies and minds moving together. Trends in cognitive sciences.
[Tomasello2005] Tomasello, M., Carpenter, M., Call, J., Behne, T., and Moll, H. (2005). Understanding and sharing intentions: The origins of cultural cognition. Behavioral and brain sciences, 28(5).